Handling BLOBs
Binary Large OBjects require special management, at least, in a scenario where the objects are truly large rather than just "binary".
RISE, by default, generates interfaces assuming BLOBs to be large. This means that BLOB attributes aren't included in argument lists, or return sets, of standard entity operations such as
Get and
Set. If, however, your BLOBs are known to be limited in size you may manually add them to the standard methods and, thus, handle them just like any other attribute. Otherwise, you need to rely on the file chunking mechanism described below.
In a scenario where a BLOB could be truly large, you need to divide it into pieces, transferred one by one, to bypass underlying message size limitations. To facilitate this RISE implements the method sterotypes Upload and Download. The Upload stereotype is used when transferring the data of a BLOB attribute to the server. The Download stereotype is used when reading BLOB attribute data from the server.
These methods are named Download<entity name><attribute name> and Upload<entity name><attribute name> by default.
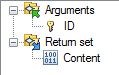
Rules for the Download method stereotype:
- The method requires the ID, of the instance to be read, as an argument.
- The method returns the binary data.
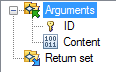
Rules for the Upload method stereotype
- The method requires the ID, of the instance to be updated, as an argument
- The method requires the binary data to be written.
RISE does not support the use of Download and Upload methods within
composed methods. To use these methods in high-level methods you need to package them in
custom methods, handling the actual chunking.
A code generator supporting Download and Upload stereotypes should, in extent to rules above, generate an interface sufficient for controlling a multi-part transaction. This means that the code generator may add further arguments and/or return set data to upload/download methods to control the transaction.
|
Download
-
Loop over the download method until it returns end-of-transaction.
-
Pass NULL as the transaction identifier in the initial call and use the transaction identifier returned by the initial call in subsequent calls.
-
For each call, pass the number of bytes read so far a the starting point for reading.
-
Pass a suitable chunk size as the max number of bytes to read.
Note, if you know the file to be smaller than some max size you may, of course, retrieve it with a single call specifying the max size as your chunk size. |
Upload
-
Loop over the upload method until you've uploaded the entire flag.
-
Pass NULL as the transaction identifier in the initial call and use the transaction identifier returned by the initial call in subsequent calls.
-
Set the end-of-transaction flag when uploading the last part of your file.
Note, if the file is already available on your server - which is the case for web applications - there's no point in chunking the upload. Simply, upload it as a single block by setting the end-of-transaction argument. |
The IDocument example
We extend out sample entity, Document, with a BLOB, Content, intended to hold the actual content of a document.
where the Content attribute is created according to below.
This will generate two methods, DownloadDocumentContent and UploadDocumentContent, with model signatures according to the images below.
| Download | Upload |
 |  |
