|
|
|
How to model
The Marshal editor displays the open models in tabs, and you can work with multiple models simultaneously. On the left hand side of the tab is a tree view representing the model itself, and on the right hand side is a property grid displaying all the properties of the selected tree node. Every node has its own set of properties defining how data should be exported and possibly imported.
The basic steps of modeling are always the same. Regardless of whether the purpose of the model is to archive business objects, publish contents, enable system integration, migrate from one system to another, log records or export for business intelligence or data mining purposes, you should: - Identify the business object you're working with and add it as the
 root node of the model. This is the Artist in the below example. root node of the model. This is the Artist in the below example. - Select a harvester, see Harvesters, for the node and provide the configuration required for the harvester to connect to the data source.
- Browse the data source and select the properties (columns) you're interrested in. These are added as leaf elements
 , or attributes , or attributes  , to the model tree. If the harvester doesn't support browsing, you need to manually add the ones you want. , to the model tree. If the harvester doesn't support browsing, you need to manually add the ones you want. - Add query nodes
 to harvest further objects related to the root node, i.e. the Releases of an Artist. This involves repeating 2 and 3 for each added query node. It's possible to add query nodes to other query nodes, not only to the root node, to accomplish any depth, such as the Tracks of a Release. Each added query node needs to be related to its parent node, in order to receive the proper input. Unrelated query nodes are yellow flagged to harvest further objects related to the root node, i.e. the Releases of an Artist. This involves repeating 2 and 3 for each added query node. It's possible to add query nodes to other query nodes, not only to the root node, to accomplish any depth, such as the Tracks of a Release. Each added query node needs to be related to its parent node, in order to receive the proper input. Unrelated query nodes are yellow flagged  . . - Go through the model to assure consistent naming and use of elements and attributes. In particular, make sure binary data is either embedded or stored as files (see Data processors). You may also add placeholders
 or parent harvesters to give the XML the structure you want or to match a given XSD. or parent harvesters to give the XML the structure you want or to match a given XSD.
In scenarios where the output of the export is persistent, rather than just acting as the input to next step in a larger process, you need to address the issue of how it's stored in the file system. Typically, when the Marshal model is used to define objects that are to be archived, published or logged, you'd want to store each object in a separate file and to have the ability to define the storage folder structure. This is all possible, see File output for details on this topic.
Image 1, A sample Marshal model
The root node.
The root node has four categories of properties, XML, Harvester, Import and Information. The XML properties define the XML output files, the harvester properties define how the information is harvested, the import properties define how data is imported and finally, the information properties give a short description of the model. The root node is basically a query node, with some additional properties. The root node can contain Query Nodes, Placeholders and Columns (Leaves). Right click on the root node to add child nodes. Read more about the root node in the article The Root Node.
A query node.
The query nodes have three categories of properties, XML, Harvester and Import. The harvester properties describe how data is retrieved from the source system, the XML properties describe how the data is stored in the resulting XML file, and the import properties describe how the retrieved data, or portions thereof, is transferred to other systems. Query nodes can contain query nodes, placeholders and columns. Right-click on the query node to add child nodes. Read more about query nodes in the article Query Nodes.
A placeholder.
The placeholder is not a carrier of data, but rather a means of organizing data. Read more about the Placeholder Node in the article Placeholder Nodes.
The column node contains properties describing the source column, such as column name and data type as well as information about how the data in the column should be stored in the export. The symbol indicates that the node is exported as an element, the symbol indicates that the node is saved as an attribute, and the  symbol indicates that the node is exported as inner text. Read more about the Column Node Properties in the article Column Nodes.
The Node State
The state of each node in the tree is visualized by the different colors, green, blue, yellow and red.
| Green |
The node is ready to be exported, and the Creation property is set to Auto (default). The element is created at export as a result of harvesting. |
| Blue |
The node is ready to be exported and the Creation property is set to Manual. The element/attribute or any sub elements/attributes will not be created at export as a result of harvesting, but can optionally be added at a later time by e.g. a post processor or a leaf data parser. |
| Yellow |
Some of the node settings are incorrect. If you hover the cursor over the node in the tree, an error message is displayed. The error must be corrected before an export can be executed. |
| Red |
The user has chosen not to export the node, i.e. the Export property is set to false. The data of the node is however available during execution, e.g. to use in relations or data processors, but it will not be exported to XML. |
Sample Export
Image 2 displays a sample export made using the model, displayed in image 1, above. Notice that the Lyrics column is saved as an element while all other column are saved as attributes. Also notice that some nodes are red, i.e. are not exported. The Id nodes are however used to relate the releases to the artists, and the tracks to the releases.
If you want to use the exported data later on to retrieve additional information, you would probably chose to export these fielda as well. We chose to exclude these columns from the export to make the result more readable.
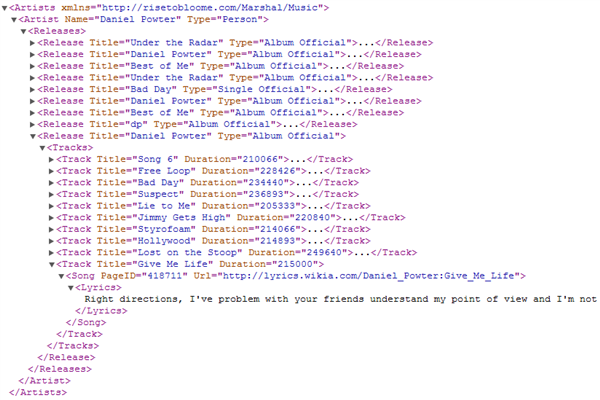 Image 2, A sample export |
|
The Root Node
|
| The root node has four categories of properties, XML, Harvester, Import and Information. The XML properties define the XML output files, the harvester properties define how the information is harvested, the import properties define how data is imported and finally, the information properties give a short description of the model. The root node is basically a query node, with some additional properties. |
|
|
Query Nodes
|
| The query nodes have three categories of properties, XML, Harvester and Import. The harvester properties describe how data is harvested from the source system, the XML properties describe how the data is stored in the resulting Xml file, and the import properties describe how the retrieved data, or portions thereof, is transferred to other systems. |
|
|
Placeholder Nodes
|
| The placeholder is not a carrier of data, but rather a means of organizing data. The placeholder only has one category of properties, XML. The properties in this category describe how the placeholder should be named and stored in the XML export. It is often a good idea to add a placeholder to reflect that a Query Node can have multiple children of the same type. |
|
|
Column Nodes
|
| Column nodes contain three categories of properties, XML, Source and Data Processor. The XML properties define how the data in the column should be stored in the export files, the Source properties describe the source data as it is defined in the source system, and using the Data Processor properties you configure a data processor to manipulate the harvested data. |
|
|
|
|
