Marshal XmlEditor for batch processing
The Marshal XmlEditor is a flexible utility for batch processing of XML files. It allows you to define a set of operations to be applied on XML files in a file structure.
The main use cases are:
- Verify a batch of XML files to make sure the information needed is really there and in the format agreed upon.
- Extend or modify a large set of XML files where, for some reason, re-exporting is impratical or not an option.
- Go through a set of XML files and extract or analyze part of their content for indexing, import or registration purposes.
The XmlEditor comes with a set of operations for finding, adding, deleting and changing the nodes (elements and attributes) of an XML document. However, real world applications often require more specific logics or functionality, such as integration with a remote system. To facilitate this Marshal XmlEditor provides an easy-to-use
database operation. It also allows definition and execution of
custom operations and
listeners.
Marshal XmlEditor is intended to be used in conjunction with other software in the Marshal suite, such as the Marshal Editor and Archiver. See section below for more details on
how to run the batch processing.
The Marshal XmlEditor is available for download
here!
How to configure
In order to process XML files you need a configuration script. This script (it's an XML file too) can be designed using the Marshal XmlEditor GUI. Simply, launch the Marshal XmlEditor from the startmenu, design your script and save!
The example below shows a script for processing all XML files belonging to the http://mynamespace namespace. In each file it looks for an owner element and, if found, it adds an insuranceNumber attribute which is assigned a value using a custom function. It then checks if the owner element has a gender attribute and, if so, deletes it.
The script configuration consists of four parts:
- A filter section giving control over what XML files that are actually processed.
- A traversal section for controlling the file and directory life-cycle.
- A namespace section for specifying the namespaces used in the various operations.
- A main part; an operation tree allowing you to define your operation sequence.
1. Filter section
| Name pattern | Mandatory! Only files whose name matches this pattern will be considered for processing. |
| Namespace Uri | Optional! If provided, only files whose document element belongs to this namespace will be processed. |
| AIP only | If set to true, only files stored in a folder the same name will be processed, i.e. abc.xml is processed if stored in folder abc. |
If multiple filter settings are specified the file must meet them all in order to be processed! And, actually, there's a fourth potential filter. A custom listener, see below, may opt out a file. This allows for more complex criterias than those builtin.
The filter criterias are evaluated in the following order:
IF file name matches the name pattern THEN
IF AIP rule is disabled OR file name matches folder name THEN
IF NOT opted out by custom listener THEN
IF no namespace uri OR document namespace matches the namespace uri THEN
2. Traversal section
| No recursion | If set to true, no sub-directories will be entered during traversal and, thus, only files in the root directory of the batch will be processed. |
| Ignore changes | If set to true, no changes will be made to the XML file, ie all changes are lost on completion. If set to false (default), all changes to the XML are made persistent by updating the original XML file on disk. |
| Custom listener | This allows you to specify a custom component that listens in on the traversal process to manage files and directories, see section on how to build a listener.
- Assembly file is the path of the assembly containing the listener class.
- Class name is the complete name, including namespace, of the class implementing the listener.
- Client data is just a string passed to the listener. Use it for configuration purposes.
|
3. Namespace section
In the namespace section you tie various namespace to prefixes. These prefixes may then be used in xpath expressions throughout the operations tree. Typically, you would add a prefix for the main namespace used in the XML documents. If you're unfamiliar with xpaths, you'll find an excellent
xpath tutorial at W3Schools.
4. Operations tree
The operations tree is a set of linked operations to be run top-down where each operation acts on the output of its parent operation. Thus, in the example above, the AddNode is executed prior to FindNodes @gender and they'll both be executed once for each result returned by FindNodes p:owner. Root operations, i.e. those with no parent such as the FindNodes p:owner, operates on the document element node, ie the outermost element of the document.
All operations, except DeleteNode, require further configuration. The available operation properties are displayedwhen selecting an operation in the operations tree, see image above.
| Operation type | Description | Returns |
| AddNode | Adds an attribute or an element to the input node. | Returns the newly created node. |
| CustomCode | Use this call your own code. Creates an instance of a class, found in an external assembly, and calls its Perform method, see section on how to implement a custom operation. | Returns whatever the custom code decides to return. |
| Database | Executes any SQL statement such as select, insert, update, exec or delete. Use this to update the XML file with content from a database or vice versa, see database operation for more details. | Returns a list of elements, an attribute or the input node depending on the configuration of the operation. |
| DeleteNode | Deletes the input attribute or element. | Returns the owning element when deleting an attribute and the parent element when deleting an element. |
| IfNode | Executes an xpath expression in the context of the input node and checks the number of resulting nodes. | Returns the input node itself if and only if the xpath resulted in a valid number of nodes. |
| IfValue | Matches the node value against a regular expression. | Returns the input node itself if and only if its value matched the regular expression. |
| RequireNode | Executes an xpath expression in the context of the input node and aborts execution unless it results in a valid number of nodes. | If valid, the input node itself is returned, ie not the nodes of the xpath. |
| RequireValue | Matches the attribute or element value against a regular expression and aborts on mismatch. | If valid, the input node itself is returned. |
| FindNodes | Use this to navigate within the XML document. Executes an xpath expression in the context of the input node.
Visit w3schools for references and tutorials on xpaths. | Returns all nodes matching the expression. |
| GeneratePDFA | Produces PDF/A versions of existing documents. See PDF/A operation below for more details. | Returns the element added for the produced PDF/A. |
| SetConstant | Use this to replace, append or prepend the an element or attribute value with a constant. | Returns the node it operated on. |
| SetRegex | Use this to wash the value of an element or attribute using a regular expression. If the regular expression doesn't match the node value isn't modified. | Returns the node it operated on. |
| SetXPath | Use this to replace, append or prepend the element or attribute with the value of a source element or attribute found using an xpath expression. If the xpath doesn't return a source node, the target node is left unchanged. | Returns the node it operated on. |
The
CustomCode operation could be used to implement any logics or funtionality and it's most certainly needed when it comes to system integration. However, for sheer XML validation and manipulation the built-in operation set is fairly complete. Use it rather than custom code to assure the maintainability and flexibility of your processing solution!
There are no variables available, so storing intermediate results is a bit tricky. However, the XML structure is in memory only until the operation tree's completed and, thus, you can store intermediate results as temporary attributes or elements. Just remember to delete them, not to mess up the final XML document, when they are no longer needed.
Note that RequireNode and RequireValue will terminate the batch execution unless the required conditions are met. That is, they won't just protect the current XML document but the entire batch of documents. To safeguard a single document, use IfNode and IfValue instead and attach whatever operations needed to their output.
4.1 The Database operation
A Database operation allows execution of SQL statements as part of the batch processing. Use it to update a database using data from the XML file or to extend the XML file with database info.
The below example shows the properties available for a Database operation. In this case, it fetches the name of the capital of a country, based on the country attribute, and adds the result as an attribute, named capital, to the XML.
A statement can be parameterized using query marks (?) in the SQL statement. In runtime, these query marks are replaced by values retrieved from the XML document using the provided Input xpaths. In case of multiple parameters, note that the Input xpaths list is ordered.
Any parameter passed to the SQL statement is passed as a text string. In case on non-text columns, the underlying database must be able to convert the input string or you'll need to provide explicit conversion as part of the SQL statement.
As for the output of the operation there's a number of options:
- If no output is needed, leave the Output node property empty. In this case, the XML document isn't affected and the return of the operation is the input node passed to the operation.
- If results are to be added to the XML document enter an Output node. The operation will return the nodes it has added to the document.
- Set Output type to Attribute for scalar operations, returning a single result.
- Set Output type to Element when returning multiple rows or columns.
If the input node, passed to the database operation, is an attribute any result nodes will be added to the parent element of the input attribute.
Data fetched from the database is automatically converted to text before it's inserted into the XML. The following conventions are applied on non-text data:
- Numbers are stored with period as decimal separator.
- Dates are stored in ISO 8601, that is YYYY-MM-DD.
- Booleans are stored as true or false.
- Binary data is encoded using Base64.
4.2 The Generate PDF/A operation
The GeneratePDFA operation supports adding long-term versions of documents to the XML structure. This operation requires the Marshal OAIS PDFA software to be installed on the computer.
The input to GeneratePDFA is an XML attribute, typically an xlink:ref, acting as a reference to the original document. A PDF/A version is created and stored alongside the original document. Finally, a reference to the new PDF/A is added to the XML.
The output of GeneratePDFA is the XML element that contains the PDF/A document reference. The example below scans the XML for any xlink and, provided it's a .docx file, generates a watermarked PDF/A version.
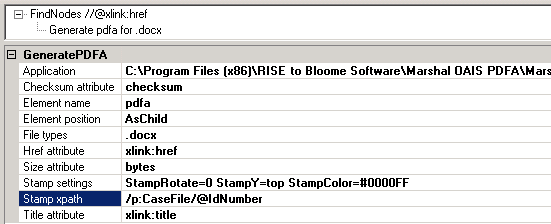
| Application | Path to Marshal OAIS PDFA application |
| File types | Comma separated list of file extensions eligible for conversion. Typically, this could be ".rtf, .odf, .doc, .docx" or something similar. |
| Element name | Name of XML element created for the PDF/A |
| Element position | Position where the PDF/A XML element is inserted, in relation to the original document element. Supported positions are sibling and child. |
| Href attribute | Name of the XML attribute containing the reference to the PDF/A document. Typically, xlink:href. |
| Size attribute | Optional! Name of XML attribute containing the size, in bytes, of the PDF/A. |
| Checksum attribute | Optional! Name of XML attribute containing the MD5 checksum of the PDF/A. |
| Title attribute | Optional! Name of XML attribute containing the title (file name) of the PDF/A. Typically, xlink:title. |
| Stamp xpath | Optional! An xpath for obtaining a value from the XML to use as watermark when creating the PDF/A. For instance, grab the case file number or the invoice number and use it as an imprint on the PDF/A. |
| Stamp settings | Optional! This allows modification of the stamp style and position. Default is a red stamp, placed at the lower-left corner along the left edge. A value of "StampRotate=0 StampY=top StampColor=#0000FF" will create a blue stamp at the upper-left corner along the upper side. |
How to run
The actual file processing can be run in manual (interactive) mode or in batch mode.
To run manually simply push the
button and select to root folder of the file structure to process. During execution a progress window is shown. It displays what file is currently processed as well as statistics on the number of folders scanned and files processed.
Batch mode means starting the application with specific command line arguments. When in batch mode the application remains hidden and errors are reported to the computer event log as well as on the "standard output". The XmlEditor supports two different command lines.
- simple mode: <root directory> <config file>
- Marshal Archiver post-processor, see separate documentation. In this case, add the path to the configuration file as an extra 6th argument.
Don't forget to quote the arguments when running from a command prompt.
Custom extensions
The Marshal XML Batch Editor allows extension of its code base. There are two types of extensions:
custom operations and
file system listeners. In both cases, these are plain .NET assemblies containg classes providing whatever functionality you need.
You need no SDK (Software Development Kit), or any kind of redistributable, to implement or use an extension. Instead, the XML Batch Editor places requirements on the signature (name, arguments and return value) of the methods and relies on dynamic loading of the extension.
There's a builtin extension browser accessible by pushing the

button. It allows you to see the classes and methods, in an assembly, that could be used as extensions. By default, the browser dialog lists the assemblies used in the current configuration script.
Developers of reusable extensions could add a Description attribute (System.ComponentModel.DescriptionAttribute), for documentation purposes, to their extension classes and methods. The content of this attribute will be displayed when browsing the extension.
How to a implement custom operation
A custom operation is a class, in an assembly, implementing the Perform method. Use it to extend Marshal XmlEditor with whatever data processing or integration you need.
XmlNode node, /* the input element or attribute to operate on */
XmlNamespaceManager manager, /* namespaces defined in the calling script */
List<XmlNode> nodes, /* output container whereto put the output nodes */
string clientData, /* custom argument to support parametrization. */
string filePath, /* full path of current XML file */
object listener /* current batch listener, if any */
The return value of the method is used to indicate if the XML document's been changed or not. If the method has changed the XML it should return true. As for the output container, nodes, a method that edits or adds a node would typically return that node through this container.
The clientData is the string entered in the property grid when configuring the operation. The full, absolute, path of the current XML file is in filePath. Avoid operating directly on the content of the file since it might not be consistent with XML currently loaded in memory. Use the node and manager instead! The listener is an instance of your custom listener class, if any. Its scope is the entire batch execution.
Your Perform method could skip arguments it doesn't need, starting from the end. For instance, bool Perform() is a fully valid signature and bool Perform(XmlNode, XmlNamespaceManager, List<XmlNode>) will be sufficient for most operations. However, there must be exactly one Perform method in each custom operation class so polymorphism isn't allowed.
An instance of your custom operation class, ie a new object, will be created for each call to the Perform method. This means you can't use your object to store state between calls. Instead, you need use a
listener for this purpose or rely on static variables, a memory cache or why not a database.
The below c# snippet implements a complete custom operation. It replaces the input node value with the number of rows in theTable. We're using clientData to pass in the database connection string. In a real application, use the input XmlNode and XmlNamespaceManager to retrieve whatever XML document data's needed for your operation.
using System; using System.Collections.Generic; using System.Data.Odbc; using System.Text; using System.Threading.Tasks; using System.Xml;
namespace TestCustomAssembly { [System.ComponentModel.Description("Counts and returns the number of rows in theTable")] public class CountStar { [System.ComponentModel.Description("Pass DB connection string as client data")] public bool Perform(XmlNode node, XmlNamespaceManager manager, List<XmlNode> nodes, string dbConn) { using (OdbcConnection cnn = new OdbcConnection(dbConn)) { cnn.Open(); using (OdbcCommand cmd = cnn.CreateCommand()) { cmd.CommandText = "select count(*) from theTable"; int count = (int)cmd.ExecuteScalar(); if (node is XmlElement) { node.InnerText = count.ToString(); } else { node.Value = count.ToString(); } } } nodes.Add(node); // Output is the input node itself return true; // Signal document changed } } } |
In order to use the above custom code in a script you need to add a CustomCode operation to the operations tree and configure it according to:
How to implement a listener
A listener is a class, in an assembly, implementing all or some of the Enter, Exit, Begin, End and OptOut methods. It allows custom code to listen in on the traversal of the file system. You need a listener in order to manage the files and directories during processing.
public void Enter(
string path, /* full path of the directory entered */
string clientData /* custom argument to support parametrization */
)
The Enter method is invoked per directory before scanning it for files and sub-directories. This means, files added to the directory by the Enter method are eligible for processing.
public void Begin(
string path, /* full path of the file to process */
string clientData /* custom argument to support parametrization */
)
The Begin method is invoked per file that meets the specified filter requirements but before operation sequence is applied on it. Thus, Begin isn't called for all files. It also means, there's no point in modifying the file at this stage, it's too late!
public void End(
string path, /* full path of the file processed */
string clientData /* custom argument to support parametrization */
)
The End method is invoked per file after processing it. It's called when the batch process is completely finished using the file and, thus, the End method could be used to post-process or delete the file.
public void Exit(
string path, /* full path of the directory exited */
string clientData /* custom argument to support parametrization */
)
The Exit method is invoked per directory when done processing its file and sub-directories. This means, the Exit method could delete the directory without affecting what's processed.
public bool OptOut(
string path, /* full path of the file that could be opted out */
string clientData /* custom argument to support parametrization */
)The OptOut method is invoked per file as part of the process of establishing whether to process it or not. If OptOut returns true the file is opted out, ie it won't be processed and, thus, neither Begin nor End will be called for this file. Use OptOut to select files on other criterias than those builtin or use it to protect the XmlEditor from opening broken XML files that would cause the batch process to stop. If the name filter is set to *.* and AIP only is disbled, any and all files found during traversal of the file structure will be passed to OptOut. If not opted out, file xml content must still meet the namespace criteria, if any, in order for it to be processed.
For all of the methods, you may skip the arguments, starting with the last one, if the method doesn't need it.
During execution the methods are called in the following order:
Traverse directory
Enter directory
For each correctly named file
If not OptOut file and namespace is valid
Begin file
File's processed!
For each sub-directory
Exit directory
An instance of the custom listener class, ie a new object, is created per batch execution. This means that the state of your object persists throughout the batch but not between batches.
The below c# snippet implements a complete listener that dumps a trace of the batch execution to file. Running it'll show the order in which the file system is traversed.
using System; using System.IO; using System.Text;
namespace TestCustomAssembly { public class Trace { private int _indents = 0;
public void Enter(string dirPath) { File.AppendAllText("trace.txt", new string(' ', 4 * _indents++) + "--> " + dirPath + "\r\n"); }
public void Exit(string dirPath) { File.AppendAllText("trace.txt", new string(' ', 4 * --_indents) + "<-- " + dirPath + "\r\n"); }
public void Begin(string filePath) { File.AppendAllText("trace.txt", new string(' ', 4 * _indents) + filePath + " ... "); }
public void End() { File.AppendAllText("trace.txt", "ok!\r\n"); } } } |
To avoid getting stuck on broken files the above example class could be extended with an OptOut method.
public bool OptOut(string filePath) { try { System.Xml.XmlDocument doc = new System.Xml.XmlDocument(); doc.Load(filePath); return false; } catch (Exception) { File.AppendAllText("trace.txt", new string(' ', 4 * _indents) + filePath + " ... opted out!\r\n"); return true; } } |
Let's wrap it up by combining a listener with a custom operation. In this case, we'd like to extend the XML file with a self referencing attribute, an xlink referring to the file itself. We're assuming we've received somekind of package, so we're only interested in the path relative to the package itself.
The listener extracts the root path when the traversal begins and the Perform method then uses the listener to extract a relative path from the full file path. The rest of the code is just XML stuff to make sure the xlink gets properly created.
using System; using System.Collections.Generic; using System.Text; using System.Xml;
namespace TestCustomAssembly { public class Listener { protected string _root = null; public string Root { get { return _root; } }
public void Enter(string dir) { if (_root == null) _root = dir; } }
public class SelfRef { public bool Perform(XmlNode node, XmlNamespaceManager manager, List<XmlNode> nodes, string clientData, string fileName, Listener listener)
{ string prefix = node.GetPrefixOfNamespace("http://www.w3.org/1999/xlink") ?? "xlink"; if (node is XmlElement && node.Attributes[prefix + ":href"] == null) { XmlAttribute attr = node.OwnerDocument.CreateAttribute(prefix, "href", "http://www.w3.org/1999/xlink"); attr.Value = Uri.EscapeUriString(fileName.Substring(listener.Root.Length).Replace('\\', '/').TrimStart('/')); node.Attributes.Append(attr); nodes.Add(attr); return true; } return false; } } } |
And the other way around, should you gather data from the XML in the Perform method for later use in the End method you'd, typically, create a listener with some data store that's reset on Begin, populated by Perform methods and, finally, used on End.
